Facebook AI Research에서 발표한 논문으로, 앞서 리뷰했던 ResNet의 1저자인 Kaiming He가 저자로 참여하였다.
교수님이 용어를 정리하고 숙지하는 데에 초점을 맞추는 것을 추천하셔서 잘 모르는 개념과 용어를 세세하게 정리하려고 하였다.
정리하다보니... 나는 모르는 게 정말 많음을... 깨달았ㄷr....
https://arxiv.org/abs/1911.05722
Momentum Contrast for Unsupervised Visual Representation Learning
We present Momentum Contrast (MoCo) for unsupervised visual representation learning. From a perspective on contrastive learning as dictionary look-up, we build a dynamic dictionary with a queue and a moving-averaged encoder. This enables building a large a
arxiv.org
[ Momentum Contrast for Unsupervised Visual Representation Learning (2019) ]
✦ Abstract
본 논문은 Unsupervised visual representation learning을 효과적으로 하기 위한 방법으로 Momentum Contrast (MoCo)를 제안하였다.
- Unsupervised Learning : 비지도 학습, 레이블이 없는 데이터에서 패턴을 학습하는 방법
- Representation Learning (Feature Learning) : 표현 학습, 데이터에서 의미있는 정보를 추출해 이해와 처리를 쉽게 만드는 표현을 자동으로 만드는 학습 방법
⇒ Unsupervised Visual Representation Learning : 레이블이 없는 이미지 데이터에서 의미 있는 feature를 추출하는 학습 방법
contrastive learning을 dictionary look-up처럼 생각한 관점으로부터 queue와 moving averaged encoder로 dynamic dictionary를 구성하였고, 이를 통해 크고 일관적인 딕셔너리를 즉석에서 만들어가며 학습한다.
ImageNet에서 좋은 분류 성능 보였고, MoCo로 학습된 표현이 downstream task에도 잘 전이되었다. 특히, 다양한 데이터셋에서 레이블을 사용해서 학습한 모델보다 큰 마진으로 좋은 성능을 보였다.
➡️ 즉, MoCo로 인해 많은 vision task에서 비지도 표현 학습과 지도 표현 학습 간의 격차가 크게 줄었다고 할 수 있음.
✦ Introduction
NLP는 GPT, BERT의 사례를 보면 알 수 있듯이, unsupervised representation learning이 큰 성공을 거두었다. 반면, CV에서는 여전히 supervised learning이 주류이고, unsupervised learning 방법이 뒤쳐져 있다. 본 논문에서는 해당 현상이 각 분야의 signal space의 차이에서 기인했을 것이라고 말한다.
NLP : discrete signal space (ex. word)
CV : continuous, high-dimensional signal space + human communication을 위한 구조 아님 (ex. image)
최근 CV 분야에서 contrastive loss를 이용한 접근법을 사용한 unsupervised representation learning이 연구되고 있다. 해당 접근법은 dynamic dictionary를 구축하는 것으로 생각될 수 있다.
※ 딕셔너리 관련 정리
- encoder : 이미지를 벡터로 만드는 네트워크 (query, key를 생성할 때 사용함)
- query : 현재 학습 대상인 데이터 샘플 (anchor sample)의 인코딩된 벡터
- key : query의 비교 대상이 되는 벡터
- dictionary : 여러 key들이 저장된 비교 대상 목록
- dictionary look-up : 어떤 입력 (query)에 대하여 매칭되는 key를 찾음
➡️ 인코더가 딕셔너리 룩업을 수행하도록 학습되어진다. 이는 인코딩된 쿼리가 매칭 키와는 비슷하도록, 다른 키들과는 다르도록 학습하는 것이고, 학습은 contrastive loss를 최소화하는 방향으로 진행된다.
dynamic dictionary란, key들이 랜덤으로 샘플링되고, key encoder가 학습 도중에 업데이트될 수 있음을 의미한다. 또, 논문 내내 large and consistent dictionary를 구축해야 한다고 강조한다. 딕셔너리 사이즈가 클수록 풍부한 negative samples로 인해 연속적이고, 고차원 공간을 더 잘 샘플링할 수 있다. 또한, 딕셔너리에 있는 키들이 같거나 비슷한 encoder로 표현되어야 쿼리와 키의 비교가 일관적이다. 즉, key encoder가 업데이트되어도 딕셔너리 내의 key들의 표현이 일관적이어야 한다.
➡️ 기존의 contrastive loss를 사용한 매커니즘들은 이 두 가지 측면에서 한계가 존재한다.
✦ Related Work
1️⃣ Loss functions
손실 함수의 일반적인 정의는 모델의 예측과 고정된 타겟 사이의 차이를 측정하는 것이다.
ex)
L1 loss : L1 \ loss = \frac{1}{N}\sum_{i=1}^{N}|(y_i-\hat{y}_i)|
L2 loss : L2 \ loss = \frac{1}{N}\sum_{i=1}^{N}(y_i-\hat{y}_i)^2
cross-entorpy : CE = -\sum _iy_i \cdot log(\hat{y}_i)
margin-based loss : zero-one loss, hinge loss,..

Contrastive loss는 representation space에서 샘플 쌍의 유사도를 측정한다. 두 샘플 간의 유사도를 기반으로 비슷한 것(positive pair)은 가까워지도록, 다른 것(negative pair)은 멀어지도록 학습하는 손실 함수이다. 인풋을 고정된 타겟과 매칭하는 것이 아닌, 타겟이 학습 중에 계속 바뀔 수 있고, 네트워크에 의해 계산된 data representation으로 정의될 수 있다. 그래서, Contrastive learning은 비지도 학습 연구의 핵심이라고 할 수 있다. (비지도 학습에서는 고정된 레이블이 없으므로)
2️⃣ Pretext tasks
pretext task (선행 과제)는 모델이 진짜로 풀고 싶은 과제는 아니지만, 좋은 표현을 학습하기 위해 임시로 푸는 과제이다. 그 범위가 매우 넓은데 input을 복원하는 것, pseudo-label을 만들어서 학습하는 것 등이 있다.
- input 복원 : Denoising auto-encoders (노이즈 제거), Context auto-enxoders (마스킹한 부분 복원), Cross-channel auto-encoders (colorization, 색상 복원)
- pseudo-labels 사용 : Transformation of a single image (한 이미지의 다양한 변형을 같은 class로 예측), Patch ordering (패치 순서 맞추기), tracking (객체 추적), segmentation, clustering, ...
많은 pretext task는 contrastive loss function의 형태에 기반한다.
✦ Method
- Contrastive Learning as Dictionary Look-up
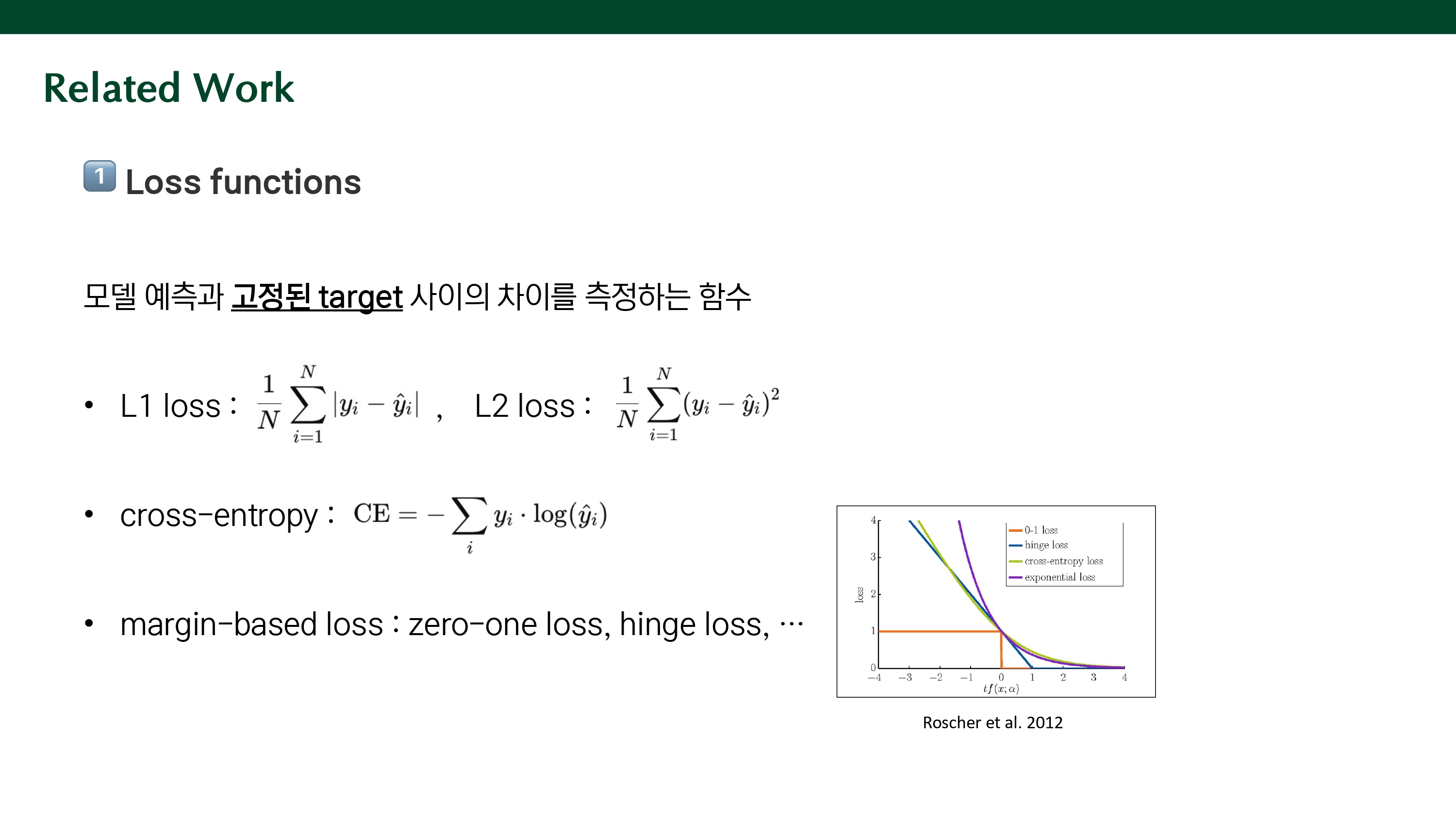
contrastive learning은 딕셔너리 룩업을 하도록 인코더를 학습한다고 할 수 있다. 인코딩된 쿼리를 q, 인코딩된 키들을 k0, k1, .. 이라고 할 때, q와 매칭되는 단일 키가 존재하고 이를 positive key인 k+라고 한다. q가 이 k+와 유사하고 negative keys과는 유사하지 않을 때 contrastive loss 값이 작아진다.
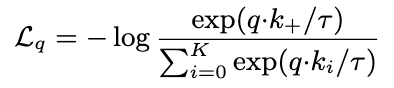
유사도는 dot product로 측정되고, 𝜏는 temperature hyper-parameter로, 확률 분포의 sharpness를 조절한다. 이러한 식을 통해 q와 k+가 유사하도록, q와 negative keys과는 멀어지도록 학습된다. 이는 unsupervised objective function으로 사용되어 인코더 네트워크를 학습시키는 기준이 된다. 또한, 이 식을 k+1 way softmax based classifier라고도 하는데, positive key 1개와 딕셔너리 내의 키 k개 중에서 쿼리와 매칭되는 정답인 positive key 1개 를 고르는 classification처럼 작동하기 때문이다. 그래서, 수도코드에서는 cross-entropy를 사용하여 loss를 계산한다.
- Momentum Contrast
MoCo의 방법론의 핵심은 key를 모아둔 딕셔너리를 선입선출의 특성을 가지는 자료구조인 queue로 구현한 것이다. 큐를 사용함으로써 과거 mini-batch에서 생성된 키들을 큐에 저장하고 계속 재사용할 수 있다. 이를 통해, 딕셔너리 사이즈가 mini-batch 사이즈와 무관하게 커질 수 있고, 더 풍부한 negative sample을 학습할 수 있다. 또한, 새 mini-batch의 키들을 큐에 추가하는 enqueue, 가장 오래된 mini-batch의 키들을 큐에서 제거하는 dequeue를 통해 딕셔너리의 샘플들이 점진적으로 교체된다. 오래된 key encoder로 인코딩된 키를 제거함으로써 딕셔너리 내 키들 간의 일관성을 유지할 수 있다.

그런데, 큐를 사용함으로써 key encoder를 back propagation으로 업데이트하기 어려워진다. 나이브한 솔루션으로 query encoder를 복사해서 key encoder로 사용하면 인코더가 빠르게 변하면서 key representation의 일관성이 크게 저하되어 accuracy가 진동하다가 수렴하지 못하는 현상이 발생한다. (위의 표에서 m=0인 케이스)
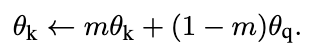
이를 해결하기 위해, momentum을 통해 key encoder를 업데이트하는 방식을 사용한다. 세타 k는 key encoder의 파라미터, 세타 q는 query encoder의 파라미터이다. 이 식을 통해 세타 q만 back propagation으로 업데이트하고, 세타 k는 세타 q의 moving average로 천천히 업데이트되도록 한다. key encoder가 천천히 바뀌면서 큐 안의 키들이 일관된 표현을 가져 안정적인 학습이 가능하도록 한다. 위 표에서 m=0.999일 때가 m=0.9, 0.99일 때보다 accuracy가 높은 것을 알 수 있다. m이 작을수록 key encoder가 빠르게 변하기 때문이다. 즉, 키 인코더가 천천히 업데이트 되어 키들 간의 일관성을 유지하는 것이 중요하다.
- Relations to previous mechanisms.

이 세 매커니즘은 모두 contrastive loss를 사용하지만, 서로 다른 dictionary size와 consistency 속성을 가진다.
(a) end-to-end 방식은 현재 mini-batch에서 생성된 키들만으로 딕셔너리를 구성한다.
딕셔너리 내의 키들이 모두 같은 인코더에서 생성되므로 키들이 일관적이라는 장점을 가진다. 또, back propagation으로 key encoder를 업데이트할 수 있다. 하지만, mini-batch 사이즈가 곧 딕셔너리 사이즈가 되어 negative sample의 수가 적어진다. 딕셔너리 크기를 키우려면 mini-batch의 사이즈를 키워야 해 GPU 메모리의 한계와 large mini-batch optimization 문제가 발생한다.
(b) memory bank는 전체 데이터셋 샘플의 representation을 모두 저장해놓고 랜덤 샘플링을 통해 딕셔너리를 만든다.
미니 배치 사이즈와 무관하게 딕셔너리를 구축할 수 있어 큰 딕셔너리 사이즈를 가질 수 있다. 하지만, memory bank에 오래 전에 인코딩된 키가 저장되어 있으므로 딕셔너리 내의 키들 간의 일관성이 크게 저하될 수 있다. 또한, memory bank에 모든 샘플의 representation을 저장해야 하므로 메모리 측면에서 비효율적이다.
(c) MoCo는 queue를 통해 큰 딕셔너리 사이즈를 가질 수 있고, 큐에서 오래된 키를 제거하고 momentum update를 통해 key encoder를 천천히 업데이트 함으로써 key들의 표현이 일관적이다. 또한, 억 단위의 데이터도 학습이 가능한 메모리 효율적인 방식이다.
✦ PseudoCode

키 인코더와 쿼리 인코더의 파라미터를 동일하게 초기화하고, n개의 샘플이 있는 미니배치에서 두 번의 랜덤 augmentation으로 positive pair를 구성한다. 각 샘플을 쿼리 인코더와 키 인코더의 넣어 인코딩하고 key에는 gradient를 안흘릴 것이므로 detach() 한다. q와 k의 유사도를 측정하여 positive logit을 만들고, positive key는 1개이므로 nx1이 된다. q와 큐 내의 k와의 유사도를 측정하여 negative logits을 계산한다. 키가 총 k개 있으므로 nxk가 된다. positive logit과 negative logit을 concat하고, 0번째가 positive logit이므로 이를 정답 레이블로 활용하여 cross-entropy loss를 계산한다. back propagation으로 쿼리 인코더를 업데이트하고, 키 인코더는 momentum update를 한다.
✦ Pretext task
- Instance Discrimination task
Unsupervised feature learning via non-parametric instance discrimination (2018)에서 제안되었던 task로, 각 이미지 (instance)를 고유한 클래스처럼 취급해서, 같은 이미지의 변형끼리는 유사하도록, 다른 이미지끼리는 달라지도록 학습하는 방법이다.
- Shuffling BN
Batch Normalization을 하면 같은 배치 안의 모든 샘플이 동일한 평균과 분산으로 정규화된다. 그런데, contrastive learning은 같은 이미지에서 나온 쿼리와 키가 positive pair가 되고, 이 둘은 같은 미니 배치 안에 존재해 비슷하게 정규화된다. 이에 모델이 이러한 통계값을 이용하여 loss가 낮아지는 솔루션을 쉽게 찾아내지만, 결과적으로 좋은 representation을 학습하지 못하는 문제가 발생하였다.
이를 해결하기 위해 여러 GPU를 사용하고, 각 GPU에서 배치 정규화를 독립적으로 수행하는 방법을 사용하였다. 쿼리 인코더에 들어가는 샘플 순서는 그대로 유지하고, 키 인코더에 들어가는 샘플의 순서를 바꾸어 GPU에 분배해 정규화를 하고, 인코딩 후에 원래 순서로 복원한다. 이렇게 다른 순서로 정규화되므로 각각 다른 통계값을 사용하게 되어 모델이 치팅하지 않게 되고, 배치 정규화의 장점을 유지할 수 있다.
✦ Experiments
(dataset)
- ImageNet-1M (IN-1M)
1000개의 클래스가 있는 ImageNet-1K와 동일 (클래스를 사용하지 않기 때문에 이미지 수로 이름 붙임)
클래스 분포가 균등함, 일반적으로 iconic object 포함함
- Instagram-1B (IG-1B)
ImageNet 카테고리와 연관된 해시태그에 대하여 인스타그램으로부터 수집한 1B 이미지 데이터
분포가 불균형한 현실적인 데이터, iconic object / scene-level image 모두 포함
- Linear Classification Protocol
비지도(pre-training)로 학습한 feature가 얼마나 유용한지를 보기 위해, 그 feature를 그대로 두고 linear classifier만 붙여서 supervised task를 수행하는 방식.
1. ResNet-50을 MoCo로 비지도 사전학습 (on IN-1M)
2. 학습된 encoder는 고정(freeze)함 → weight 안 바뀜
3. 마지막 출력 feature (global average pooling) 위에 fully-connected layer + softmax만 학습 → 이게 classifier 역할
4. 이 classifier만 supervised 방식으로 100 epochs 학습
성능 부분은 아래 PPT에 있음..
( 발표 자료 )