동기들과 딥페이크 관련 공모전에 참가하기로 해서 읽게 된 논문 !
비디오와 오디오를 사용한 점과 student-teacher 프레임워크가 흥미로웠다..!
https://arxiv.org/abs/2201.07131
Leveraging Real Talking Faces via Self-Supervision for Robust Forgery Detection
One of the most pressing challenges for the detection of face-manipulated videos is generalising to forgery methods not seen during training while remaining effective under common corruptions such as compression. In this paper, we examine whether we can ta
arxiv.org
[ Leveraging Real Talking Faces via Self-Supervision for Robust Forgery Detection (2022) ]
✦ Abstract
얼굴 조작 영상 탐지 (detection of face-manipulated videos)의 시급한 가장 시급한 과제 중 하나는 훈련 중 보지 못한 위조 기법에도 일반화(generalisation)할 수 있으면서, 동시에 압축(compression)과 같은 일반적인 변형에도 효과적으로 대응하는 것이다. 본 논문에서는 실제 대화 얼굴 영상을 활용하여 이러한 문제를 다루었다. 실제 대화 얼굴 영상은 자연스러운 얼굴과 행동에 대한 풍부한 정보를 포함하며, 온라인에서 대량으로 얻을 수 있는 이점이 존재한다.
RealForensics는 두 단계로 구성되어 있다.
1️⃣ 실제 영상에서의 시각적, 청각적 모달리티 간의 관련성을 활용하여 자기 지도 크로스 모달 학습 방식 (self-supervised cross-modal manner)으로 시간적으로 밀도 높은 영상 표현 (temporally dense video representations)을 학습한다. 이 표현들은 얼굴 움직임, 표현, 신원 (identity) 등과 같은 요소를 포착한다.
2️⃣ 학습한 표현들을 forgery detector가 예측해야 하는 타겟으로 설정하여 일반적인 이진 위조 분류 작업 (binary forgery classification task) 을 수행한다.
※ cross-modal learning : 한 모달리티의 정보로 다른 모달리티의 정보를 예측하는 학습 방법
✦ Introduction
딥러닝 기반 탐지기 (deep learning-based detectors)는 분포 내 데이터 (in-distribution data, 훈련 데이터와 분포가 같은 데이터)에 대해 높은 정확도를 달성하지만, 훈련 과정에서 보지 못한 새로운 조작 방법으로 생성된 영상에 대해서는 성능이 급격히 떨어진다. 다양한 프레임 기반 방법 (frame-based methods, 인풋이 단일 프레임)들이 cross-manipulation generalisation 문제를 해결하기 위해 제안되었다. 그럼에도 불구하고, 많은 방법들이 새로운 위조 유형에 성능이 크게 떨어지거나 압축과 같은 흔한 변형에도 쉽게 손상되는 저수준 (low-level) 단서에 의존하는 경향이 존재한다.
많은 합성 방법이 생성 과정에서 시간적 일관성 (temporal consistency)을 고려하지 않기 때문에 시간 차원 (temporal dimension)을 포함하는 것이 성능을 향상시킬 수 있다는 것은 합리적이다. 하지만, 네트워크에 비디오 데이터를 단순히 학습시키면 훈련 중 본 적 있는 위조에 대해 오버피팅될 수 있다.
1) LipForensics : 대규모 립리딩(lipreading) 데이터셋에 대해 사전 학습 후, 네트워크의 일부를 고정시켜 low-level 단서에 집중하는 것을 방지하였다. 이는 cross-manipulation generalisation에 대한 높은 성능과 일반적인 변형에 대한 robustness를 보였다.
그러나, 라벨이 존재하는 데이터셋에서 사전 학습해야 하므로 확장성 (scalability)이 제한되고, 입 영역에만 집중하고, 네트워크의 약 1/3을 고정해야 하므로 성능을 희생할 가능성이 존재한다.
2) FTCN : 모든 spatial convolutional kernel의 크기를 1로 제한하여 cross-manipulation genaralisation을 향상시켰다.
그러나, 이와 같은 방법은 압축에 대한 robustness가 저하될 수 있다.
➡️ 본 연구는 가짜 영상이 시간에 따라 비정상적인 얼굴 움직임과 표정을 보인다는 것에 기반하였다. 이러한 단서들은 고수준 (high-level)이며, 저수준 콘텐츠를 손상시키는 변형 (compression, blurring, ...)에 대해 강하다. 라벨이 없는 실제 영상을 활용하여 detector가 이러한 단서에 집중할 수 있도록 유도하는 것이 가능할까?
이를 위해, 두 단계의 접근법을 제안한다. (RealForensics)
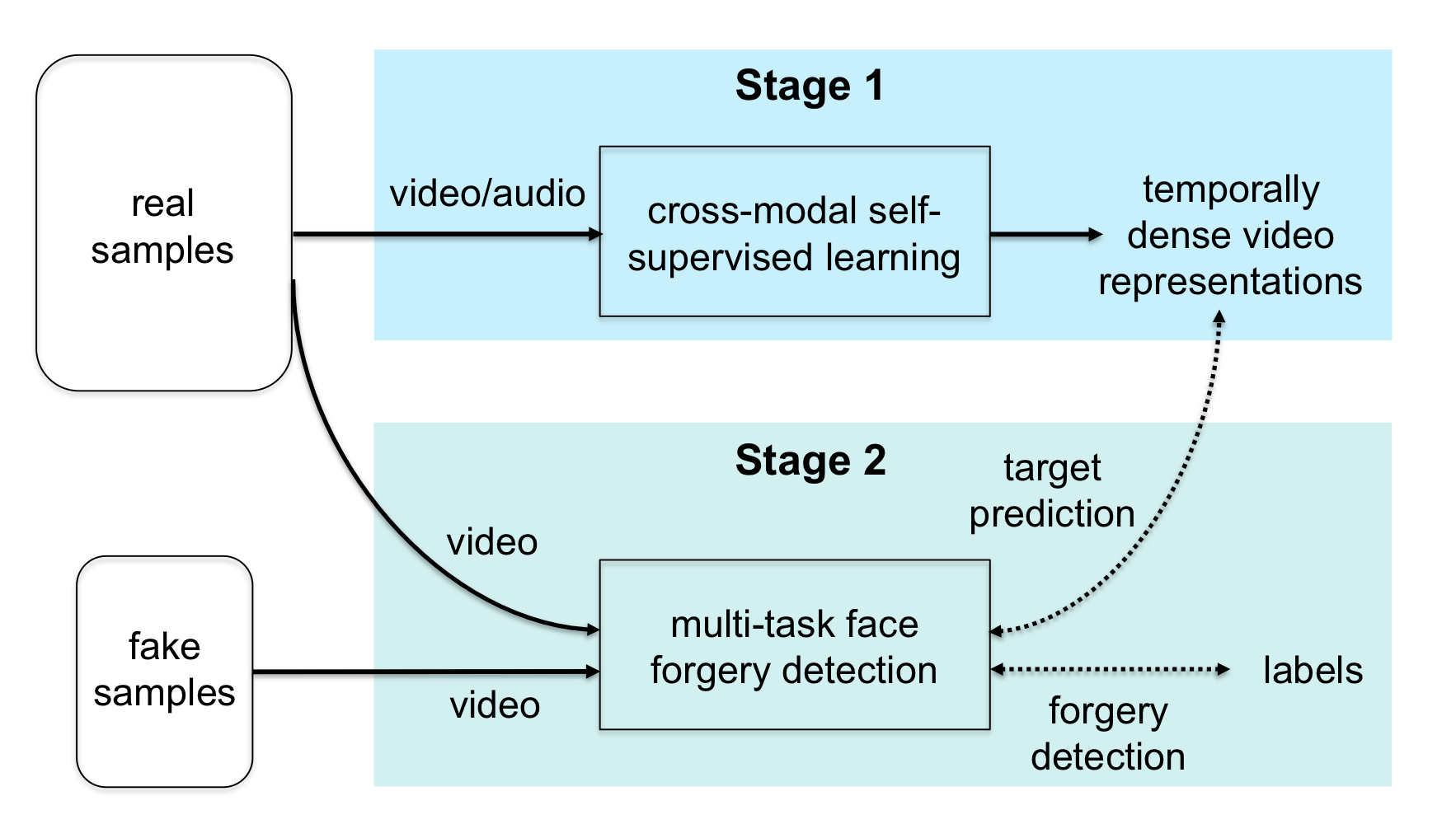
Stage 1 : 실제 영상의 시각, 청각 모달리티 간의 관련성을 활용해 self-supervision 방식으로 temporally dense한 영상 표현을 학습
Stage 2 : BYOL에서 영감을 받아, cross-modal student-teacher framework 사용 (위조 탐지와 예측을 동시에 수행)
이를 통한 연구의 기여는 다음과 같다.
1. 대량의 실제 대화 얼굴을 사용하는 2단계 탐지 접근법을 제시하여 강력한 일반화 성능과 robustness 높임
2. temporally dense representations를 학습하는 non-contrastive self-supervised framework
3. cross-manipulation generalisation, 흔한 변형에 대한 robustness에 대한 실험에서 SOTA 성능 달성, 성능에 기여한 요소 분석
※ cross-manipulation generalisation : 새로운 위조 기법에 대해서도 성능 유지하는 것
✦ Method
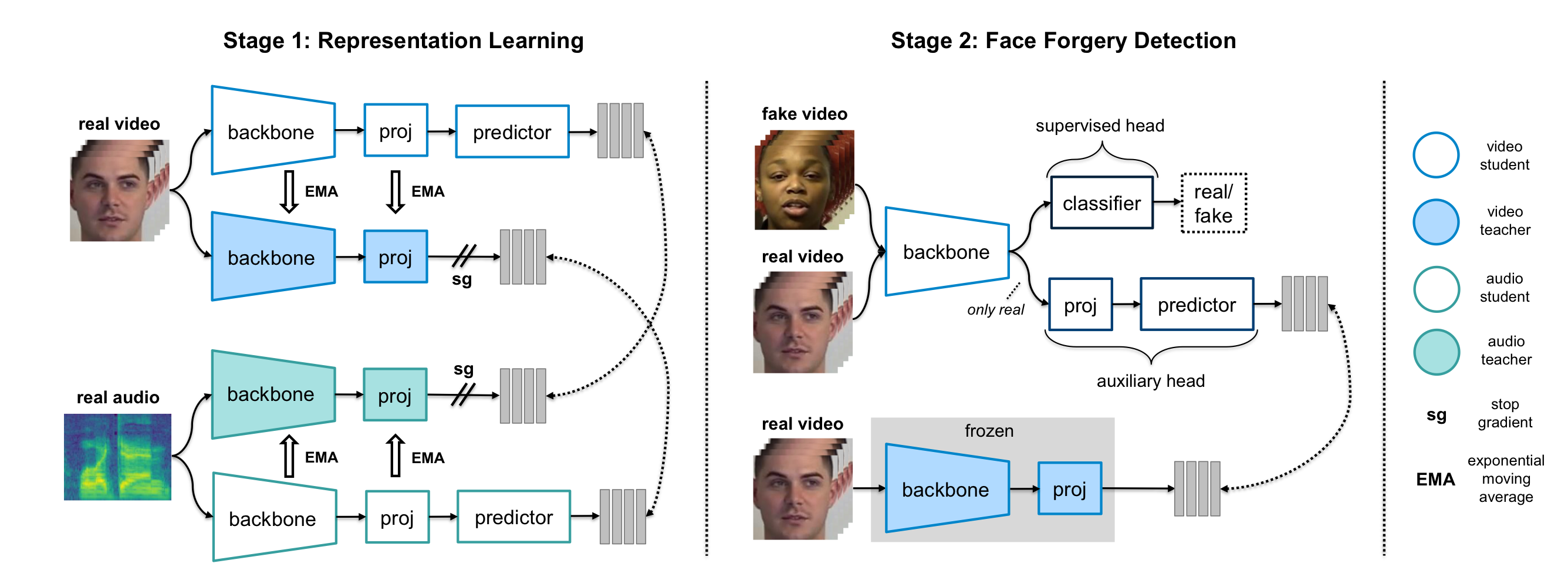
- Stage 1 : representation learning
실제 비디오와 그에 상응하는 오디오를 사용하여 얼굴 외형과 행동에 관련된 정보를 포착하는 영상 표현을 학습하는 것을 목표로 한다. 이러한 단서는 시간적으로 세밀하므로 (temporally fine-grained), temporally dense representations (frame-wise representations, 프레임마다 하나의 임베딩)를 학습하기를 원한다. 부정 샘플 대비 (contrasting negatives) 없이 student-teacher framework를 사용하는데, 이는 이미지 표현 학습에서 SOTA를 달성하였고, 네트워트가 두 모달리티에 의해 공유되는 모든 정보를 얻도록 유도하고, negatives를 저장할 큰 batch size나 큐가 필요하지 않다는 이점이 있다.
각 모달리티에 대해 한 쌍의 student-teacher 네트워크를 사용한다. 교사는 다른 모달리티의 학생이 예측해야 하는 타겟을 생성한다. 학생 네트워크는 실제 비디오와 오디오를 입력으로 받아, 다른 모달리티의 교사 네트워크가 생성한 타겟을 예측하는 방식으로 학습한다. 학생 네트워크는 교사와 동일한 구조이지만, 추가적으로 predictor (예측기)를 포함한다.
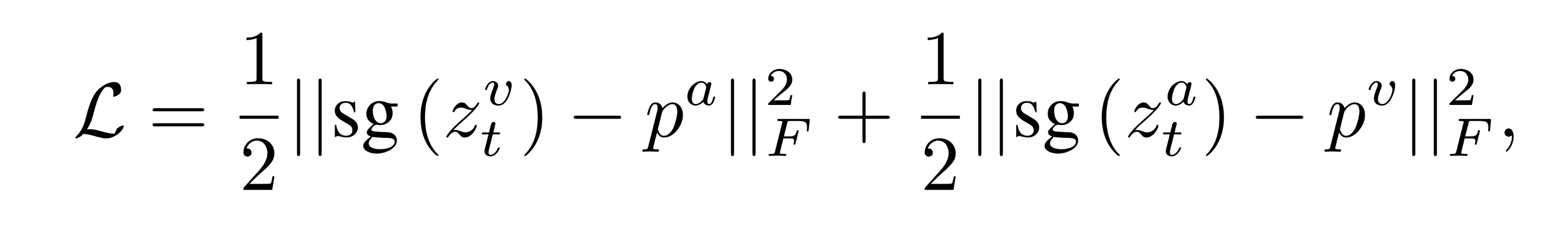

학생 네트워크는 gradient descent에 의해 loss를 최소화하도록 최적화된다. 교사 네트워크는 학생 네트워크의 가중치에 대해 exponential moving average (EMA) 방식을 사용하여 업데이트 되는 momentum encoders이다.
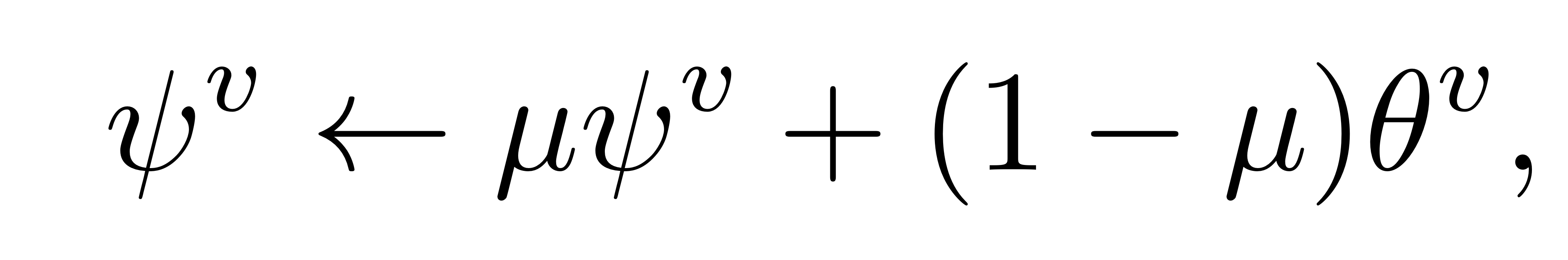
(뮤 : momentum parameter, 1에 가까움 / 프사이 : teacher weight / 세타 : student weight)
* Transformer as predictor
BYOL은 모든 샘플에 대한 표현이 동일해지는 representation collapse를 피하기 위해 predictor가 필수적임을 보여주었고, 본 연구에서 같은 상황을 관찰할 수 있었다. BYOL은 global representations를 출력하고, MLP를 predictor로 사용하였지만, 본 연구에서는 dense representation 학습을 위해 얕은 transformer를 사용하였다.
* Random masking
비디오의 프레임 내의 랜덤한 직사각형 영역을 0으로 설정하고, 연속적인 임의의 프레임 삭제하였고, 오디오에 대해서는 연속된 오디오 프레임과 주파수 bin을 삭제하였다. 이러한 랜덤 마스킹은 학생 네트워크의 입력에만 적용되었고, 이를 통해 학생 네트워크가 문맥을 활용해 누락 정보를 추론하도록 유도하고, 인풋의 특정 특성에만 과도하게 의존하는 것을 방지한다.
- Stage 2 : multi-task forgery detection
이 단계는 비주얼 기반 위조 탐지기를 학습하는 것을 목표로 하므로 1단계에서 학습된 오디오 학생-교사 네트워크를 사용하지 않는다. 1단계에서 학습된 비디오 교사가 네트워크가 예측해야 하는 타겟을 생성하고, 동시에 네트워크는 위조 탐지를 수행한다. (교사 네트워크는 고정됨) 보조 손실 (auxiliary loss)를 사용해 네트워크가 얼굴 외형과 행동의 고수준 시공간적 특징에 집중함으로써 진짜와 가짜 영상을 구분하도록 유도할 수 있다.
네트워크는 공유된 backbone과 두 개의 헤드로 구성된다.
-> supervised head (for forgery classification loss) / auxiliary head (q, for target prediction loss).
{theta}_{b} : backbone f의 가중치, {theta}_{s} : supervised head의 가중치, {theta}_{a} : auxiliary head의 가중치


보조 손실 {L}_{a}는 학생 네트워크가 교사 네트워크의 출력을 예측하도록 학습하는 손실 함수이다. supervised loss {L}_{s}는 binary cross entropy의 logit-adjusted 버전이다. 이는 클래스 불균형 (class imbalance, 진짜 데이터가 많은 것)을 다루기 위함이다.
✦ Experiments
평가 지표로 정확도 (accuracy)와 AUC (area under the receiver operating characteristic curve)를 사용하였다. 비디오에 대해서는 단일 비디오를 겹치지 않고 균일하게 나누어 모든 클립의 예측값을 평균하였다.
- Cross-manipulation generalisation

배포된 탐지기는 훈련 중에 보지 못한 방법으로 만들어진 위조 영상을 인식할 수 있어야 하며, 이는 쉽지 않은 작업이다. Table 1은 FF++ 데이터셋에 대해 특정 유형을 제외한 나머지 유형을 훈련한 후에 특정 유형에 대한 성능을 나타낸 결과이다. RealForensics는 auxiliary labelled supervision을 사용하지 않았고, 네트워크의 많은 부분을 고정하여 제한하거나 spatial convolution을 제거하지 않았고, 테스트 시 오디오를 사용하지 않았음에도 SOTA 성능을 달성하였다. 또한, 동일한 증강 방식을 사용한 위조 데이터에 대해 학습한 CSN 네트워크보다 성능이 뛰어나 실제 데이터 활용하는 접근 방식의 효과를 입증하였다.

FF+에서 학습한 단일 모델을 CelebDF-v2, DFDC, FaceShifter, DeeperForensics와 같은 훈련 중 보지 못한 도전적인 데이터셋에서 테스트하여 cross-dataset generalization을 평가하였다. 우리의 방법은 모든 데이터 셋에서 SOTA를 달성하여 기존 학습보다 더 발전된 위조에 대해서도 좋은 성능을 보였다.

또한, 더 적은 네트워크 파라미터로 다른 관련 모델보다 더 높은 일반화 정확도를 달성하였다.
- Robustness to common corruptions

탐지기는 소셜 미디어에서 비디오가 겪는 흔한 변형에 대해서도 견고해야 한다. Table 4는 각 변형에 대한 모든 강도의 평균 AUC를 나타낸다. RealForensics는 저수준 단서에 집중하는 frame-based 방법보다 흔한 변형에 덜 취약하였다.
✦ Limitation
- 훈련 시에 높은 계산 비용이 필요하지만, 테스트 시에는 문제가 없다.
- 비디오를 인풋으로 입력 받으므로, 단일 이미지에 적용할 수 없다.
- 좋은 성능에도 불구하고, 잘못된 예측을 할 때 높은 확신을 가지고 예측하므로 출력된 확률값 해석에 주의가 필요하다.



